Why I love the H-index
The H-index – a small number with a big impact. First introduced by Jorge E. Hirsh in 2005, it is a relatively simple way to calculate and measure the impact of a scientist (Hirsch, 2005). It divides opinion. You either love it or hate it. I happen to think the H-index is a superb tool to help assess scientific impact. Of course, people are always favourable towards metrics that make them look good. So let’s get this out into the open now, my H-index is 44 (I have 44 papers with at least 44 citations) and, yes, I’m proud of it! But my love of the H-index stems from a much deeper obsession with citations.
As an impressionable young graduate student, I saw my PhD supervisor regularly check his citations. Citations to papers means that someone used your work or thought it was relevant to mention in the context of their own work. If a paper was never cited, and perhaps therefore also little read, was it worth doing the research in the first place? I still remember the excitement of the first citation I ever received and I still enjoy seeing new citations roll in.
The H index: what does it mean, how is it calculated and used?
The H-index measures the maximum number of papers N you have, all of which have at least N citations. So if you have 3 papers with at least 3 citations, but you don’t have 4 papers with at least 4 citations then your H-index is 3. Obviously, the H-index can only increase if you keep publishing papers and they are cited. But the higher your H-index gets, the harder it is to increase it.
One of the ways in which I use the H-index is when making tenure recommendations. By placing the candidate within the context of the H-indices of their departmental peers, I can judge the scientific output of the candidate within the context of the host institution. This is a useful because it can be difficult to understand what is required at different host institutions from around the world. It would be negligent to only look at H-index and so I use a range of other metrics as well, together with good old fashioned scientific judgement of their contributions from reading their application and papers.
The m value
One of those extra metrics I use was also introduced by Hirsch, and is called m (Hirsch, 2005). M measures the slope or rate of increase of the H-index over time and is, in my view, a greatly underappreciated measure. To calculate the m-value, take the researchers H-index and divide by the number of years since their first publication. This measure helps to normalise between those at the early or twilight stages of their career. As Hirsch did for physicists in the field of computational biology, I broadly categorise people according to their m value in the table below. The boundaries correspond exactly to those used by Hirsch.
| m-value – H-index/yr | Potential for Scientific Impact |
| <1.0 | Average |
| 1.0-2.0 | Above average |
| 2.0-3.0 | Excellent |
| >3.0 | Stellar |
So post-docs with an m-value of greater than three are future science superstars and highly likely to have a stratospheric rise. If you can find one, hire them immediately!
The H-trajectory
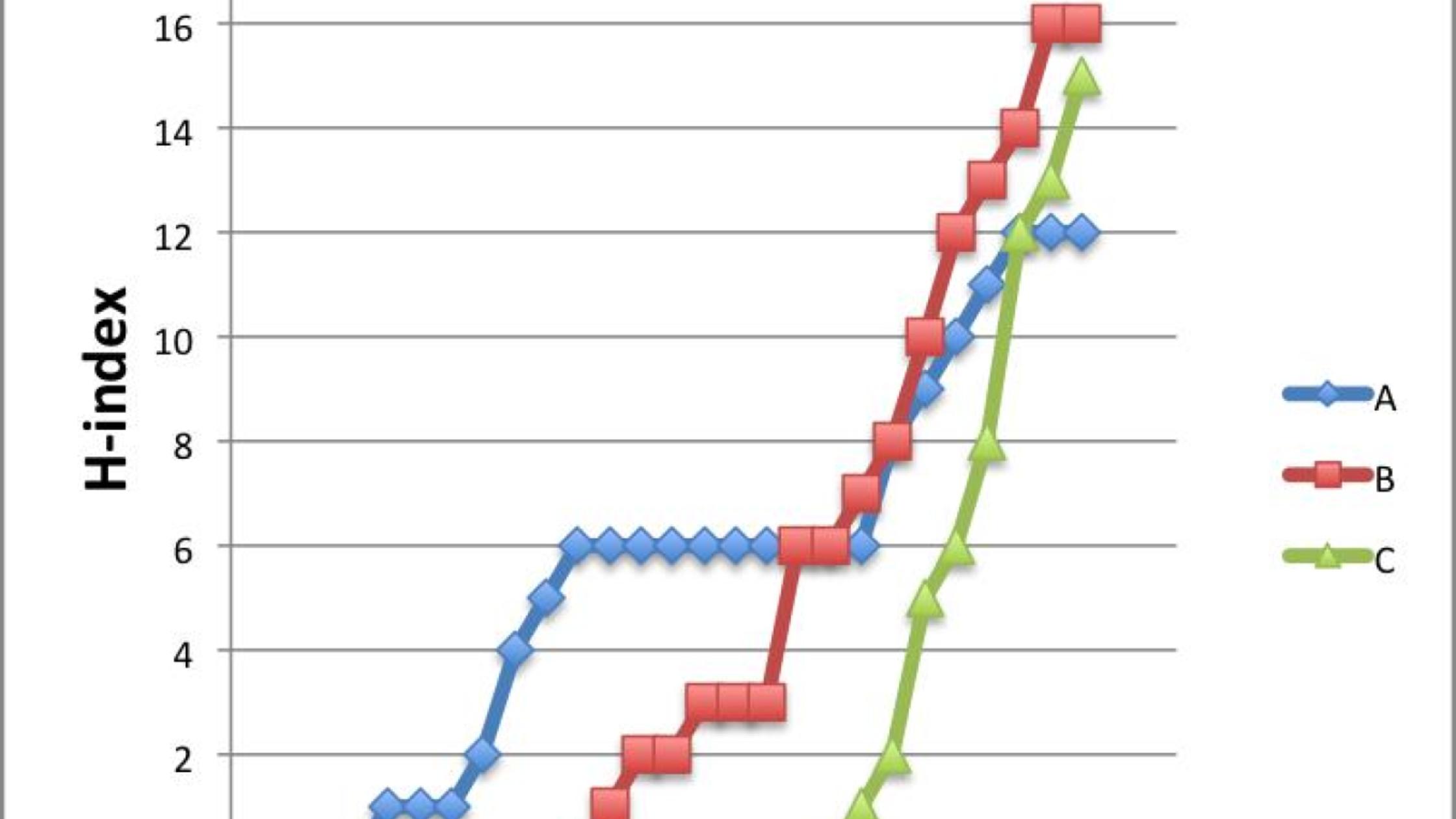
The graph below shows the growth of the H-index for three scientists – A, B and C – who respectively have an H-index of 12, 15 and 16. I call these curves a researcher’s H-trajectory.
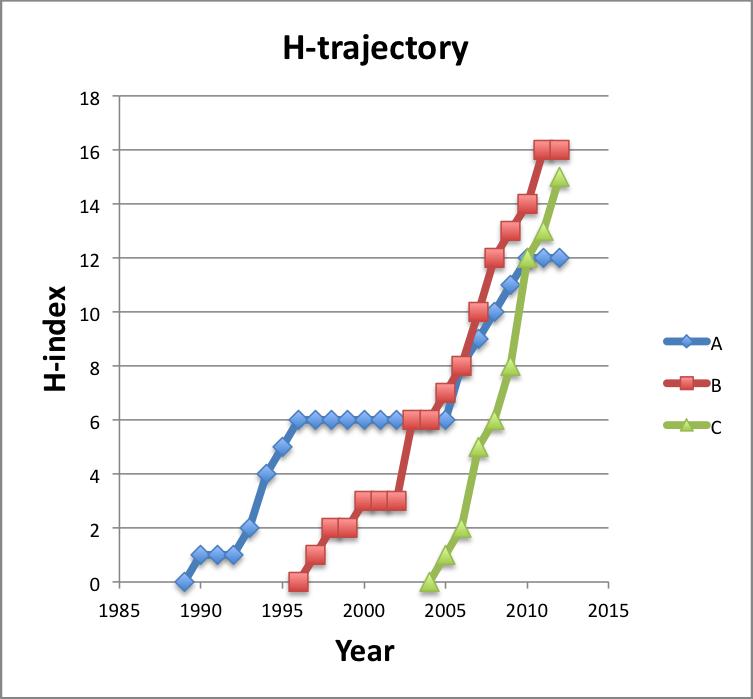
If we calculate their m-value, then we find that A has a value of 0.5, B has 0.94 and C a value of 1.67. So while each of these researchers has a similar H-index, their likelihood for future growth can be predicted based on past performance. Recently, Daniel Acuna and colleagues presented a sophisticated prediction of future H-index using a number of several features, such as number of publications and the number in top journals (Acuna et al. 2012).
As any serious citation gazer knows, the H-index has numerous potential problems. For example, researcher A who spent time in industry has fewer publications, people with names in non English alphabets or very common names can be difficult to correctly calculate, different fields have widely differing authorship, publication and citation patterns. But even considering all these problems, I believe the H-index is here to stay. My experience is that ranking scientists by H-index and m-value correlates very well with my own personal judgements about the impact of scientists that I know and indeed with the positions that those scientists hold in Universities around the world.
Alex Bateman is currently a computational biologist at the Wellcome Trust Sanger Institute where he has led the Pfam database project. On Novembert 1st, he takes up a new role as Head of Protein Sequence Resources at the EMBL-European Bioinformatics Institute (EMBL-EBI).
References
J.E. Hirsch. An index to quantify an individual’s scientific research output. Proc. Natl. Acad. Sci. 102, 16569-16572.
D.E. Acuna, S. Allesina & P. Konrad. Predicting scientific success. Nature 489, 201-202.
The problem with the H factor is that it is, to a considerable extent, a measure of how old you are. The m index is supposed to correct this but it can distort things by assuming a linearity that just isn’t there in the development of a scientist.
The alternative I propose is the H5Y factor. It is the H factor, but calculated only on citations received in the past five years. This equalizes the playing field and my guess is that it is a much better predictor of performance for the next five years than H or m. Who cares what you have published thirty years ago? (unless it is still being cited, of course!)
I agree with Constantin, and would add that the m-index is particularly unfair to those who take early career breaks, since it takes several years before the penalty of having a gap after their first few papers starts to become trivially small.
Interestingly, Google Scholar’s “My Citations” pages (e.g. see my profile link for a not-so-random example!) does calculate what Constantin proposes, an H-index computed from the last five years’ citations, though they don’t call it H5Y. Personally, though I agree that this is better than H, I still think it’s a rather biased measure of quality, which more strongly reflects quantity or length of active career.
Funnily enough, I think Google are already using a better measure (which they call H5), but only for their journal rankings, not their author profiles, see e.g.
scholar.google.co.uk/citations?view_op=top_venues
This measure is the H-index for work published in the last five years, rather than just cited in the last five years, and they call this H5.
I think it would be great if Google Citations profiles showed H5 for authors, but frustratingly, Google’s FAQ indicates that they are opposed to adding new metrics:
http://scholar.google.com/intl/en/scholar/citations.html#citations
But perhaps Scopus, ResearcherID, Academia.edu, ResearchGate or similar will add H5 in the future…
[…] Crushing it Among Nobel Science Winners Why I love the H-index (not sure I’m afraid or in agreement) A Simple Way to Reduce the Excess of Antibiotics […]
Most of the H-trajectory plots that I have created for active scientists do show quite a linear trend. I only showed three in my graph above, but researcher A was the only significant deviation that I found. Creating these H-trajectory plots was not as easy as I thought it was going to be. Downloading the full citation data is time consuming given the limits imposed by SCOPUS and ISI. I also found that the underlying data for citations was not nearly as clean as I expected.
I agree that it is important to be able to take account of career breaks so that we do not penalise researchers unfairly. Being able to plot the H-trajectory might help spot these. But as I mentioned in the article these metrics should only be used as part of a wider evaluation of individuals outputs. I tend to agree with the google view on the proliferation of metrics that this could lead to more confusion than it solves. But H5-like measures seem like another reasonable way to normalise out the length of career issue.
I find Google Scholar far better than ISI. It is updated more regularly and gives better representation to publications in non-English journals. I would choose it over others to calculate any sort of index.
Ok, but why would the h-index given by an online calculator ever be higher than the number of publications?
I agree with Alex. I had the same experience, whether to recruit post-docs, young group leaders or evaluate tenure (and even in one case head of large institute). After 3, 10, 20 or 30 years of research, the h-index and m numbers are very good to evaluate not only the brilliance at one point, but also the steady success. You do not hire the genious who had only one magic paper and nothing else significant. The likelyhood that the magic happens again is very low.
You have to compare with peers though. Having been an experimental neuroscientist and a computational modeller I know that the citation patterns are quite different. However, when using the H-index to compare people, we are generally in a situation where we compare similar scientists.
All that of course being a way to quickly sort out A, B or C lists, and uncovering potential problems (100 publications and h-index of 10). After that step, you need to evaluate the candidates more attentively, using interviews etc. But interestingly you very rarely read the publications. In the first screen you have too many of them and in the second you do not need them anymore.
(and I am “excellent” yeah! Not “stellar” though. One delusion I have to get rid of 😉 )
Interesting logic exercises. What about superstars who translate their work into patents/products and can not publish due company confidentiality, company goals, etc? Patents are not cited anywhere close to publications. Organic journals often have low impact factors and low citation rates as the animal studies in higher impact journals always overshadow the original synthetic papers. A good friend of mine has an H-index of only 7 but has designed a block-buster drug (and several other promising leads)–I would trade my inflated H-Index (product of a hot, speculative field) in a minute to have his stock options–oh and that drug that helps tens of thousands everyday. Sorry to burst that bubble–H-Indexers. Used to be a believer but I have now seen the light. Yep–and I would also take that “flash in the pan” invention of PCR (and the Nobel) over 50 years of high citations. One flash can have a greater impact than a thousand scientists over a thousand years.
[…] is reading about the H-index from someone with a big one. Does side matter? When it comes to how many times your works get cited it […]
Thanks for the helpful discussion. I just googled “what is a good h-index” and yours was the first thing to come up. I think as with any single statistic it has limitations, but overall is a decent reflection of output, especially for comparison with similar applicants for a position.
I’d convert your m index based on h-index/(fte years working since first paper) which would take account of breaks/part-time working. This would particularly help women remain competitive in the context of extended periods of part-time working. So my 10 years since 1st paper would turn into 10-1-(5*0.6) = 6, so my m index is 2 = 12/6 instead of 12/10. Woo!
Anyway I don’t think anything will stop me checking my citations obsessively and google citations is the easiest place I’ve found to keep my publications organised.
Amen. Coming from someone who was stuck too long in a company in which publishing in the open domain was a big no-no. H-index is one number, but it is not _the_ number. Neither are Google’s variations, and so forth. For example, IQ is another number, it has it uses, but it clearly isn’t _the_ number either. Me not like metrics so much.
I like the m-value, but it has the unfortunate effect of penalising the early starter. For example, someone who publishes a paper from their Hons thesis may be penalised by 3-4 years in the denominator producing their m-value when compared with someone starting publishing in the third or fourth year of their PhD. So I would take Kate’s idea further, and use FTE as THE denominator when calculating m, instead of years since first paper. This could include time spent as a PhD student, or not, as long as it was standardised.
Google Scholar gives exactly this statistic under the standard h-value.
One problem with H or M index can be how many people are actively involved in the research in a particular field. For example, there are only ~186 laboratories in the whole world working on my previous field, Candida albicans. But, right now I am working on cancer biology. Huge number of people are working in that field, hence the h index will increase dramatically.
I think that is a good suggestion. It is important to take account of career breaks when judging peoples scientific output. Its not perfect to just subtract the break length or some combination of time. Even during a career break your pre-break papers will still be cited and potentially increasing your H-index. But to a first approximation what you suggest makes good sense. It would be interesting to look at the H-trajectories of people who have taken a career break to see how it affects growth of H-index.
Yes that is a good point. Publishing a paper during your degree should be seen as a strong positive indicator in my opinion and as you say not penalise the person. OK, so lets use years of FTE employment as the denominator.
It is best to only using H-index for comparing people within the same field. I’m not sure that moving field is any guarantee of increasing H-index, but it will be easier for your H-index to grow in the large field. I guess the smart thing to do is to start in cancer biology then move to the specialist field 😉
I don’t like h index when it is used to rank journals as it basically gives a statistics about the best papers in that journal. For example if nature has a 5 year h index of 300, it only says something about those 300 papers and nothing about the thousands of other papers they published. Because of that, plos one has a very high h index, I think ranked top 30, but that just reflects the number of elite papers being published there, not the tens of thousands of junk papers it publishes..
My problem with h-index for insividuals is that it does not differentiate first author papers from contributing author papers. A tech could be put in 50 high impact papers over 5-6 years because he is in a super high impact lab for technical contributions. However a post doc in such a lab would have much fewer papers because be would be focusing on making first author papers. However in the end, the tech would have a higher h index. Is that a fair assessment? Also that tech could be a postdoc in name but doing tech work. Would such a technician postdoc be at a higher advantage to employers who only look at h index?
The extreme scenarios given to discount H-index can be absurd:
a) A tech having 50 papers! I do not know a tech that is put on 50 papers in 5 years in any lab. If such a tech exists, then he/she is a superstar tech and needs to be celebrated.
b) why penalize someone who publishes in their PhD with an m index- well you forget that if someone publishes early, then their h index will increase because their papers will start collecting citations early so even if the denominator is increased by a few years, isn’t the numerator also increased?
c) In chemistry, there was a table of the top 500, based on h-index. All on that table were superstars, by other metrics, and all the recent nobel prize winners were on that list. There was not a single name on that list who was not famous.
I agree that one can not use h index to different between h of say 15 and 20. But if someone has an h of say 60 and the other has 30, there is usually a light and day between them.
The h is here to stay.
None of the above addresses key weaknesses of the h-index – self citation and citation rings.
If you work in large collaborations and projects it is *easy* for *many* people to rack up large numbers of citations (and h-indices) by citing each others papers and by simply appearing on lots of papers for which they have done little work. At the very least I believe citations should be a conserved quantity – one citation is one citation, and if it to is a paper with 100 authors then it should not add 1 citation to *each* of those author’s records, it should add 0.01 (or some other agreed fraction dictated by author order such that Sigma (fraction) =1).
Then, self-citations, both in the form of you citing your own paper, or any papers upon which a co-author appears citing that paper should not count.
This would cut many h-indices down to size and be a much truer reflection of an individual’s contribution.
What’s your normalised (by number of authors) h-index, excluding self-citations?
[…] https://blogs.plos.org/biologue/2012/10/19/why-i-love-the-h-index/ Tweet!function(d,s,id){var js,fjs=d.getElementsByTagName(s)[0];if(!d.getElementById(id)){js=d.createElement(s);js.id=id;js.src="//platform.twitter.com/widgets.js";fjs.parentNode.insertBefore(js,fjs);}}(document,"script","twitter-wjs"); […]
Out lab publishes over 40 papers a year and has three techs contributing to almost every paper for technical work. They have higher h then postdocs.
But what is worse are PIs who do no work and don’t even read the paper but is still on the author list…apparently a common occurrence for high energy physics consortiums.
[…] h-index weaknesses with various computational models that, for example, reward highly-cited papers, correct for career length, rank authors’ papers against other papers published in the same year and source, or count just […]
There should be a metrics which weigh the author position. Typically first author does all the work. So the first authorship and the final authorship should have higher weightage compared to other authorships. Personally, I think the name appearing after the third author and before the final author should not have any weightage
[…] Many have attempted to fix the h-index weaknesses with various computational models that, for example, reward highly-cited papers, correct for career length, […]
[…] was re-reading a blog post by Alex Bateman on his affection for the H-index as a tool for evaluating up-and-coming scientists. He describes Jorge Hirsch’s H-index, its […]
1. Take out self citations
2. Take out review article citations
3. Have a negative field (topic) correction factor.
4. Have a negative correction factor for study section member, journal editor etc.
5. have a name and country correction factor.
Then let us compete…
I strongly agree about taking out citations for review articles. They totally distort the evaluation of a scientists’ worth. Reviews are cited much more highly than oritinal articles and contribute zero to the advancment of science by their authors. Less strongly, I also agree about self-citations because it is so hard to distinguish between genuine ones and irrelevant self-serving ones.
As both journal editor and study section member, I can assure you that neither capacity does anything to citations. I can’t think of anyone gratuitously citing my papers so that they can get preferential treatment. This is preposterous.
Finally, topic and country corrections are much more meaningful to apply to the final use of the h-factor than to its calculation. Whether that use is promotion, tenure, new appointment or funding, you are competing against your compatriot colleagues in the same field. Across countries, most responsible decision makers will apply a correction factor. When looking at post-doc applicants, I will rather take someone from, e.g. India with h=3 than from the US with h=5.
I do not quite agree with a country correction. Nobody cites you because you hail from a particular country. Your work is cited because its good, relevant and has helped somebody in their research and not just because you are a compatriot.
There is a bit more subtlety to country considerations. I agree that an author’s self-interest would strongly motivate them to cite the best paper that supports the point they are making, regardless of where the paper came from. However, we are judging the author here, not the paper. Across countries, there are huge discrepancies in terms of opportunities authors had to reach any given H value.
Put yourself in the position of a lab director going through post-doc applications. You narrow it down to two applicants, both H=5, one of them achieved it by working in the US, the other by working in, say, Tunisia. All other things being equal, who is more likely to have stellar performance in your lab?
This is what I mean when I say that the country correction should apply to the final use of the H, but not to its calculation.
If it comes down to selecting one among two-three people, the selection will fully be based upon how well the interview go with that person. Whether he will perform well or not will be gauged through the interview and not by the H index
[…] Source: blogs.plos.org […]
[…] but she send me a few links later on and while reading them through I slowly began to understand. This one she send me as well and helped me the most in understanding the whole […]
[…] A career in science depends more and more on quantitative measures that aim to evaluate the efficiency of work and the future potential of a researcher. Most of these measures depend on publishing output, thus many people conclude that we live in a “publish or perish” environment. Nowadays universities also face austerity measures and one could say, that we are living in “post-doc-apocalyptic” times, meaning that a large number of postdocs (working under temporary contracts) are competing for a small number of tenure positions. Altogether, universities make a very competitive environment. Quantitative indicators, like the h-index, are becoming more and more important in this competition. Should you take notice of them? If you want to work in academia, you should. You will probably see a lot of disadvantages in this output-orientated system, but this is where we are at today. Taking care of your career, might require strategic decision making, which has to take into account possibilities of improving your quantitative indicators also. What is the h-index? Despite the fact that its relatively new (it was described for the first time in 2005), the h-index has become an important measure of career development. Just today I saw an academic job offer with a minimum h-index value added to the list of requirements. The h-index is generally used for choosing candidates for promotions and grant fundings. It is very often used as an official criteria, but in other cases it can be used by referees or reviewers to evaluate research output, because it is easy for anyone to determine what is the exact value of this parameter (have a look here for a reasons to love h-index). […]
[…] h-index changes over time (though see Alex Bateman’s old blog post about “Why I love the h-index“, where he refers to the “h-trajectory”). Does the “successful […]
[…] A. Why I love the h-index. PLoS […]
[…] A. Why I love the h-index. PLoS […]
[…] on statistically assessing researchers based on publications, impact factors and H-index (Click for article on H-Index). Two people considered amongst the best scientists of the 20th century had this to […]
[…] https://blogs.plos.org/biologue/2012/10/19/why-i-love-the-h-index/ […]
h-index doesn’t make any sense. Although there are so many examples for that, few examples are given here. There is one scientist with h-index of 82 and 37,900 citations even at the beginning of her career. But she hasn’t written a single research paper in her life. Because she got the membership of many CERN groups in the world, she got her name among the thousand names given at the end of many research papers. She is not even a coauthor of any of those papers. Just because CERN members publish papers in so called US or European journals, google scholar search robot finds all those papers. Most of the CERN members got higher h-index and higher number of citations like that.
On the other hand, there are some researchers who have written 70 to 100 papers. But they have a lower h-index below 10 and less number of citations, just because google search robot can’t find even many good journals. Google search robot easily finds US journals, because it thinks that US journals are reputed journals. When I was doing my Ph. D at early nineties, I read several research papers. I found one good paper with original data of ferrite thin films published by some Japanese scientists on a Japanese journal. Few years after that, I found that some US researchers have deposited the same material on the same substrate using same techniques. But the data of US researchers are worse than the data published by Japanese researchers. But US researchers have published their worse data even after one year in US journal of applied Physics. So how can someone say that US journals are the best?
[…] weaknesses with various computational models that, for example, reward highly-cited papers, correct for career length, rank authors’ papers against other papers published in the same year and source, or count just […]
[…] PLOS Biologue: Why I love the H-index – https://blogs.plos.org/biologue/2012/10/19/why-i-love-the-h-index/ […]
[…] Corregir según la duración de la carrera académica del autor […]